

Chapter 06
A basic Router implementation
Note
A small note: we will be using the camelCase naming convention for our web framework. I plan to use this framework for my personal projects and encourage others developers to use it as well. For this reason, I need to ensure that my naming conventions align perfectly with the naming conventions used in Node.js's standard library.
We'll start building the fundamental building block of any web server framework - a Router. A router is an utility that determines how an application responds to different HTTP requests for particular URLs or in simple terms, it determines which HTTP requests should be handled by which part of the application.
Let's look at a normal node:http server, and understand why it is really cumbersome to manage different HTTP methods. Create a new project/directory, and create a new file: index.js
// file: index.js
const http = require("node:http");
const PORT = 5255;
const server = http.createServer((req, res) => {
res.end("Hello World");
});
server.listen(PORT, () => {
console.log(`Server is listening at :${PORT}`);
});
Note
We talked about what every line of server does in the chapter 5.0 - HTTP Deep Dive, but to recap: the method res.end() tells the server that everything in the response, including headers and body, has been sent and the server should treat the message as finished.
If you try to send a GET, POST, PUT request to this server using cURL:
curl --request POST http://localhost:5255
## Hello World
curl -X PUT http://localhost:5255
## Hello World
How do we identify and differentiate between different HTTP methods? Fortunately, we have req.method:
// file: index.js
const http = require("node:http");
const PORT = 5255;
const server = http.createServer((req, res) => {
res.end(`Hello from -> ${req.method} ${req.url}`); // Changed line
});
server.listen(PORT, () => {
console.log(`Server is listening at :${PORT}`);
});
If you send a request again, using cURL:
curl -X PUT http://localhost:5255
## Hello from -> PUT /
curl -X PUT http://localhost:5255/hi/there/test
## Hello from -> PUT /hi/there/test
That should have already made you think, to write actual applications using the bare node:http module, there would be lot of if and else statements in our code base. You are correct. That is why we need a Router class that abstracts away all the functionality of handling different HTTP methods and URLs and provides a clean interface to the developer.
Before we implement our Router class, let's try to write a useful web server with what we have with us.
A Toy Router
// file: index.js
const http = require("node:http");
const PORT = 5255;
const server = http.createServer((request, response) => {
const { headers, data, statusCode } = handleRequest(request);
response.writeHead(statusCode, headers);
response.end(data);
});
function handleRequest(request) {
const { method, url } = request;
let data = "";
let statusCode = 200;
let headers = {
"Content-Type": "text/plain",
};
if (method === "GET" && url === "/") {
data = "Hello World!";
headers["My-Header"] = "Hello World!";
} else if (method === "POST" && url === "/echo") {
statusCode = 201;
data = "Yellow World!";
headers["My-Header"] = "Yellow World!";
} else {
statusCode = 404;
data = "Not Found";
headers["My-Header"] = "Not Found";
}
return { headers, data, statusCode };
}
server.listen(PORT, () => {
console.log(`Server is listening at :${PORT}`);
});
Let's go through this line by line.
const { method, url } = request;
We passed the entire request object as an argument to handleRequest, we only care about two fields: method and url. So, instead of accessing the properties like request.method and request.url, we're using destructuring to get the values of method and url from the request object.
let headers = {
"Content-Type": "text/plain",
};
Since Node.js's ServerResponse.end method does not implicitly sets the Content-Type header, we're manually setting it - as we know we're only returning plain text back to the client. It is a good practice to include all necessary headers following the HTTP guidelines.
if (method === "GET" && url === "/") {
data = "Hello World!";
headers['My-Header'] = "Hello World!";
} else if (method === "POST" && url === "/echo") {
...
} else {
...
}
We are using the data variable to keep track of the content that will be sent back to the client. If the HTTP method is GET and the URL is / (which means the request URL on cURL is either http://localhost:5255/ or http://localhost:5255), we will send back Hello World! and set our custom header My-Header.
The same applies to other routes as well, where we change the data being sent, the status code, and the My-Header header according to the method and the url. If it doesn't matches our needs, we're simply sending a 404 status code, and Not Found back to the client.
Note
Sending the right headers is really important when sending data back to the client. Headers control how the client and server communicate and protect the data. If the headers are wrong or missing, bad things can happen like security problems or the application not working. So, getting the headers right is more important than the actual data being sent.
In fact you can just ignore the data, and just send an empty response with 404 status code. Every developer knows what does a 404 code means.
return { headers, data, statusCode };
We're returning the information back to the caller function - which in case is this part:
const server = http.createServer((request, response) => {
const { headers, data, statusCode } = handleRequest(request);
response.writeHead(statusCode, headers);
response.end(data);
});
Once the handleRequest function finishes executing, we get the appropriate headers, the data and the status code that needs to be sent back to the client in order to let them know "Okay we're done processing your request. Here is the result".
response.writeHead(statusCode, headers);
writeHead is a method on the ServerResponse class, which gives us the flexibility to set response headers, as well as status code. The headers should be an object with key being the header name, and value being the header value.
But what if we do not set these headers? Turns out, if you do not set headers before res.end(), Node.js implicitly sets most of the headers.
Note
The second argument can also be an array with multiple entries, but we're not going to use that.
res.end(data);
Tells the client - "I'm officially done now. Take this data".
Now, let's test our simple implementation of this "router" function.
$ curl http://localhost:5255 -v
* Trying 127.0.0.1:5255...
* Connected to localhost (127.0.0.1) port 5255 (#0)
→ GET / HTTP/1.1
→ Host: localhost:5255
→ User-Agent: curl/7.87.0
→ Accept: */*
→
* Mark bundle as not supporting multiuse
← HTTP/1.1 200 OK
← My-Header: Hello World!
← Date: Fri, 01 Sep 2023 14:49:06 GMT
← Connection: keep-alive
← Keep-Alive: timeout=5
← Transfer-Encoding: chunked
←
* Connection #0 to host localhost left intact
Hello World!
We have our header My-Header, status code of 200 and the response body Hello World!. Let's test the POST endpoint too:
curl -X POST http://localhost:5255/echo -v
* Trying 127.0.0.1:5255...
* Connected to localhost (127.0.0.1) port 5255 (#0)
→ POST /echo HTTP/1.1
→ Host: localhost:5255
→ User-Agent: curl/7.87.0
→ Accept: */*
→
* Mark bundle as not supporting multiuse
← HTTP/1.1 201 Created
← My-Header: Yellow World!
← Date: Fri, 01 Sep 2023 14:52:33 GMT
← Connection: keep-alive
← Keep-Alive: timeout=5
← Transfer-Encoding: chunked
← * Connection #0 to host localhost left intact
Yellow World!%
Perfect! Everything looks fine. Now it's time to test an URL or method which isn't covered by our handleRequest function.
* Trying 127.0.0.1:5255...
* Connected to localhost (127.0.0.1) port 5255 (#0)
→ POST /nope HTTP/1.1
→ Host: localhost:5255
→ User-Agent: curl/7.87.0
→ Accept: */*
→
* Mark bundle as not supporting multiuse
← HTTP/1.1 404 Not Found
← My-Header: Not Found
← Date: Fri, 01 Sep 2023 14:53:47 GMT
← Connection: keep-alive
← Keep-Alive: timeout=5
← Transfer-Encoding: chunked
←
* Connection #0 to host localhost left intact
Not Found%
Yes, the status code is 404 as expected. My-Header has the correct value, and the response body is Not Found. The implementation looks fine.
Transfer-Encoding: chunked
You may have noticed a new header Transfer-Encoding with the value of chunked in the output above. What is it?
In chunked transfer encoding, the data is split into separate pieces called "chunks". These chunks are sent and received without depending on each other. Both the sender and receiver only need to focus on the chunk they are currently working on, without worrying about the rest of the data stream.
This is because, we did not specify the Content-Length header, and that means we (as a server) do not know the size of the response payload, in bytes. However, one should only use Transfer-Encoding: chunked when you're sending a large payload and don't know about the exact size of payload.
There is a slight (but noticeable) performance overhead with chunked encoding when you're sending small payload to the client as chunks. In our case, we're just sending a small string "Hello, world!" back to the client.
Chunks, oh no!
The message "Hello, world!" is only 13 bytes long, so its length in hexadecimal is D. In fact we're only sending a simple looking string back to the client, but turns out the data being sent is almost 2x the size of the string Hello, world!.
Here is how it would look in chunked encoding:
D\r\n
Hello, world!\r\n
Each chunk in the response is preceded by its length in hexadecimal format, followed by \r\n (CRLF), and then another \r\n follows the data. This means that for each chunk, you have the extra bytes to represent the length and two CRLF sequences.
To indicate the end of all chunks, a zero-length chunk is sent:
0\r\n
\r\n
So, the full HTTP message body in chunked encoding would be:
D\r\n
Hello, world!\r\n
0\r\n
\r\n
Now, let's calculate the size of response with Transfer-Encoding: chunked:
- The size of the chunk in hexadecimal (
D) = 1 byte - The first CRLF (
\r\n) after the size = 2 bytes - The data ("Hello, world!") = 13 bytes
- The second CRLF (
\r\n) after the data = 2 bytes - The zero-length chunk to indicate the end (
0) = 1 byte - The CRLF (
\r\n) after the zero-length chunk = 2 bytes - The final CRLF (
\r\n) to indicate the end of all chunks = 2 bytes
In total, it becomes 23 bytes! You're actually sending back 2x the size of the payload, which is a lot of extra overhead. The bigger your response payload, the lesser the overhead.
But most of the text responses don't need chunked encoding. It's helpful for things which are large, and you may not know the size of the payload you're sending, like a file that lives on AWS S3, or a file that you're downloading from an external CDN. Chunked encoding would be a great candidate for that.
Specifying Content-Length
To get rid of Transfer-Encoding: chunked, we just have to specify the Content-Length header, with the value of the payload in bytes.
function handleRequest(request) {
const { method, url } = request;
let data = "";
let statusCode = 200;
let headers = {};
if (method === "GET" && url === "/") {
data = "Hello World!";
headers["My-Header"] = "Hello World!";
} else if (method === "POST" && url === "/echo") {
statusCode = 201;
data = "Yellow World!";
headers["My-Header"] = "Yellow World!";
} else {
statusCode = 404;
data = "Not Found";
headers["My-Header"] = "Not Found";
}
// set the content-length header to the value of length of `data` in bytes.
headers["Content-Length"] = Buffer.byteLength(data);
return { headers, data, statusCode };
}
The Buffer class provides a very useful helper method: Buffer.byteLength. If you try to make a request using cURL, you'll see the Content-Length header, and the Transfer-Encoding: chunked isn't there. Perfect.
curl http://localhost:5255 -v
## Omitted request output
→
* Mark bundle as not supporting multiuse
← HTTP/1.1 200 OK
← My-Header: Hello World!
← Content-Length: 12
← Date: Fri, 01 Sep 2023 17:25:08 GMT
← Connection: keep-alive
← Keep-Alive: timeout=5
←
* Connection #0 to host localhost left intact
Hello World!
Code reusability
We are still one step away from implementing our Router class. Before doing so, I want to talk a little bit about code-maintainability. The current way is fine, but this will go out of hand when you're going to handle a lot of routes. We should always design our programs with scalability and reuse in mind.
Let's include a global object routeHandlers and then update the code accordingly, in a way that we can easily add new routes without having to change the handleRequest function.
// file: index.js
const http = require("node:http");
const PORT = 5255;
const server = http.createServer((request, response) => {
const { headers, data, statusCode } = handleRequest(request);
response.writeHead(statusCode, headers);
response.end(data);
});
// The header that needs to be sent on every response.
const baseHeader = {
"Content-Type": "text/plain",
};
const routeHandlers = {
"GET /": () => ({ statusCode: 200, data: "Hello World!", headers: { "My-Header": "Hello World!" } }),
"POST /echo": () => ({ statusCode: 201, data: "Yellow World!", headers: { "My-Header": "Yellow World!" } }),
};
const handleRequest = ({ method, url }) => {
const handler =
routeHandlers[`${method} ${url}`] ||
(() => ({ statusCode: 404, data: "Not Found", headers: { "My-Header": "Not Found" } }));
const { statusCode, data } = handler();
const headers = { ...baseHeader, "Content-Length": Buffer.byteLength(data) };
return { headers, statusCode, data };
};
server.listen(PORT, () => {
console.log(`Server is listening at :${PORT}`);
});
Let's look at some of the weird looking parts:
// `handler` holds a function, based on the incoming HTTP `method` and the `URL`
const handler =
routeHandlers[`${method} ${url}`] ||
(() => ({ statusCode: 404, data: "Not Found", headers: { "My-Header": "Not Found" } }));
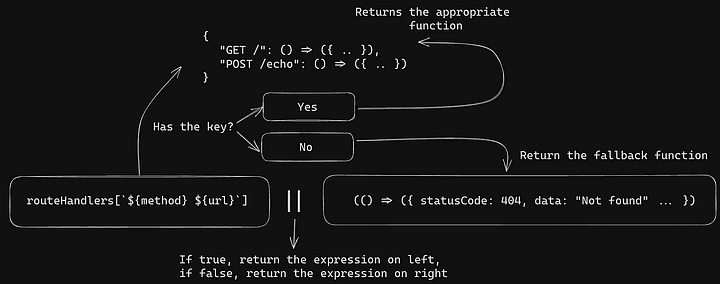
We're looking for a key in the routeHandlers object, which matches the incoming method and URL. If the key is available, we're going to use the value of that key from routeHandlers, which is in-fact a function. If the key is not found, means that we do not have a handler associated for a particular method and URL combination, we simply assign the handler variable with the value of a function that returns:
{ statusCode: 404, data: "Not Found", headers: { "My-Header": "Not Found" } }
Although we will not use the code written above in our Router, it is important to understand the significance of better design and planning ahead. As projects grow, it is easy to fall into the trap of the sunk cost fallacy. This fallacy leads us to stick with our initial approach simply because of the time and effort already invested.
Before you dive into coding, take some time to think about how your design can grow and adapt easily down the road. Trust me, it'll save you headaches later. Start off by making a basic prototype or a couple of features. Then, as things start to grow, that's the clue to dig into the design and structure of your program.
Separation of Concerns
Our route handlers are defined as properties of an object routeHandlers. If we need to add support for more HTTP methods, we can do that without changing any other parts of our code:
const routeHandlers = {
"GET /": () => ({ statusCode: 200, data: "Hello World!", headers: { "My-Header": "Hello World!" } }),
"POST /echo": () => ({ statusCode: 201, data: "Yellow World!", headers: { "My-Header": "Yellow World!" } }),
"POST /accounts": () => ({ statusCode: 201, data: "Creating Account!", headers: { ... } }),
// Add more HTTP methods
};
A general rule of thumb is - Your functions should only do what they are supposed to, or what their name says. It is called the Single-responsibility principle. Suppose you have a function with a signature of function add(x, y), it should only add two numbers, nothing else. An example of bad code, that you shouldn't do:
function add(x, y) {
// Not only adding x and y, but also writing to console, which is not expected.
console.log(`Adding ${x} and ${y}`);
// Performing a file operation, which is definitely not expected from an 'add' function.
const fs = require("fs");
fs.writeFileSync("log.txt", `Adding ${x} and ${y}\n`, { flag: "a+" });
// Sending an HTTP request, which is out of scope for an 'add' function.
const http = require("http");
const data = JSON.stringify({ result: x + y });
const options = {
hostname: "github.com",
port: 80,
path: "/api/add",
method: "POST",
headers: {
"Content-Type": "application/json",
"Content-Length": data.length,
},
};
const req = http.request(options);
req.write(data);
req.end();
// Finally adding, which is what the function is supposed to do.
return x + y;
}
However, a good example would look something like:
// This function does only what it says: adds two numbers.
function add(x, y) {
return x + y;
}
// A separate function to log the addition operation.
function logAddition(x, y) {
console.log(`Adding ${x} and ${y}`);
}
// A separate function to write the addition operation to a file.
function writeFileLog(x, y) {
const fs = require("fs");
fs.writeFileSync("log.txt", `Adding ${x} and ${y}\n`, { flag: "a+" });
}
// A separate function to send the addition result to an API.
function sendAdditionToAPI(x, y) {
const http = require("http");
const data = JSON.stringify({ result: add(x, y) });
const options = {
hostname: "cachelane.com",
port: 80,
path: "/api/add",
method: "POST",
headers: {
"Content-Type": "application/json",
"Content-Length": data.length,
},
};
const req = http.request(options);
req.write(data);
req.end();
}
// You can now compose these functions according to your needs.
logAddition(3, 5); // Logs "Adding 3 and 5"
writeFileLog(3, 5); // Writes "Adding 3 and 5" to 'log.txt'
sendAdditionToAPI(3, 5); // Sends a POST request with the result
console.log(add(3, 5)); // Logs "8", the result of the addition
While modularity and the Single Responsibility Principle are generally good practices, overdoing it can lead to its own set of problems. Extracting every tiny piece of functionality into its own function or module can make the codebase fragmented and difficult to follow. This is sometimes referred to as "over-engineering."
Here are some general considerations, that I tend to follow:
Too Many Tiny Functions: If you find that you have a lot of functions that are used only once and consist of just one or two lines, that might be an overkill.
High Abstraction Overheads: Excessive modularity might introduce unnecessary layers of abstraction, making the code less straightforward and harder to debug.
Reduced Performance: While modern compilers and interpreters are good at making things faster, if you have a lot of little functions that you call many times, it can add extra overhead if the compiler decides to not inline them.
We'll take everything we've learned so far and apply it to our Router class in the next chapter.